데이터 표현과 특성 공학 스터디 내용 요약
업데이트:
4. 데이터 표현과 특성 공학
feature engineering
데이터를 어떻게 표현하는가가 모델의 성능에 영향을 크게 미침
범주형 변수
- 텍스트로 이루어진 범주형 변수는 모델에 바로 학습시킬 수 없음
- 정성적 속성을 정량적으로 표현해줘야함
원-핫-인코딩(one-hot-encoding)
= 원-아웃-오브-엔 인코딩(one-out-of-N-encoding), 가변수(dummy variable)
- 범주형 변수 표현하는 데 가장 널리 사용
- 범주형 변수를 [0, 1]값을 가진 새로운 피처들로 표현
- pandas의 get_dummies 함수로 범주형을 모두 원핫인코딩처리
data_dummies = pd.get_dummies(data) data_dummies.values # 데이터프레임을 numpy배열로 변환, 모델 학습 가능한 형태 - 주의점
- train, test세트 나눌 때, one-hot-encoding을 먼저 적용 후에 나눠야함
- 안그러면 train세트에는 있는 피처가 test세트에는 없는 등의 문제 나타날 수 있음
- 나눈 후에도 train, test세트가 각각 같은 피처를 가지고 있는지 확인해야함
- 숫자로 표현된 범주형 특성
- 오지선다, 객관식 설문문답 등 범주형을 숫자로 입력하는 경우도 많음
- 연속성으로 처리하지 않도록 주의
- 피처를 직접 선택하여 숫자형도 원핫인코딩 가능
pd.get_dummies(df, columns=['a', 'b']) df['a'] = df['a'].astype(str) # 이렇게 문자로 형식 변경하여 진행해도 됨구간 분할, 이산화 그리고 선형 모델, 트리 모델
- 구간 분할(bining, 이산화)
- 연속성 데이터에 강력한 선형 모델을 만드는 방법 중 하나
- 한 특성을 여러 특성으로 나눔
- np.digitize(데이터, 범위)로 구간 분할
# 구간 설정 (-3, 3까지 10구간) bins = np.linspace(-3, 3, 11) # 구간에 맞게 X데이터 분할 which_bin = np.digitize(X, bins = bins) - 구간에 맞게 원-핫-인코딩
from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder(sparse=False) # encoder.fit은 which_bin에 나타난 유일한 값을 찾음 encoder.fit(which_bin) # 원-핫-인코딩 변환 X_binned = encoder.transform(which_bin) print(X_binned[:5]) # [[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] # [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] # [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] # [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] # [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]] - 구간 분할 전과 구간 분할 후
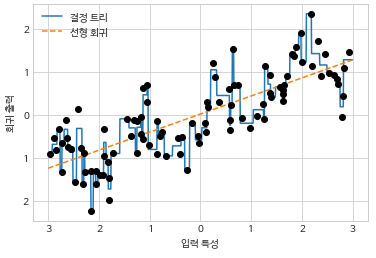

- 분할 이후 선형 모델은 유연해졌음, 하지만 결정 트리는 오히려 성능 떨어짐
- 선형 모델에서 구간 분할 적용 시 유리한 점이 많아짐
상호작용(interaction)과 다항식(polynomial)
- 원본 데이터 더하기
- 원-핫-인코더로 분할한 데이터에 원본 데이터를 붙여서 학습시키면 기울기도 학습함
- 그런데, 기울기가 모든 구간에서 일정해서, 크게 유용하지는 않음
# 원본 + 원-핫-인코더로 분할된 데이터 X_combined = np.hstack([X, X_binned]) reg = LinearRegression().fit(X_combined, y)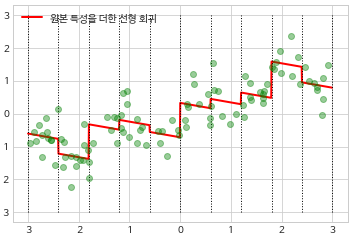
- 원본 데이터 곱하기
- 원-핫-인코더로 분할한 데이터에 원-핫-인코더 * 원본데이터로 학습시키면 각 구간별 기울기를 다르게 학습
- 곱했을 때 형태는 원핫인코더 형식 + 1이 할당된 자리에 원본 데이터가 들어간 형식
X_product = np.hstack([X_binned, X*X_binned]) reg = LinearRegression().fit(X_product, y)
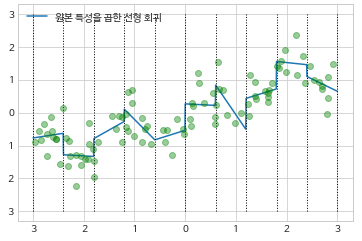
- 다항식 추가
- 원본 특성의 다항식을 추가하여 (**2, **3, **4…) 시도 가능
- 다항식 특성을 선형 모델과 함께 사용하면 다항 회귀 모델이 됨(polynomial regression)
- 고차원 다항식은 데이터가 부족한 영역에서는 너무 민감하게 동작
- 시작과 끝 부분이 급격하게 꺾이는 모습 ```python from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=10, include_bias=False) X_poly = poly.fit_transform(X) ```
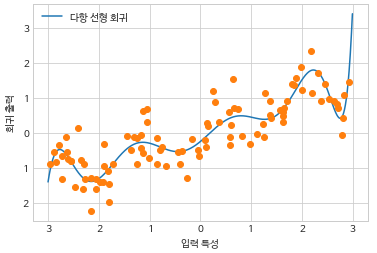
- 다항식을 추가하여 차원을 확장하면 선형에서는 다항 회귀 모델이 되며 비교적 유연해짐.
- randomforest같은 복잡한 모델에 적용 시에는 오히려 성능이 떨어질 수 있음
일변량 비선형 변환
- log, exp, sin등 수학 함수를 적용하는 것도 특성 변환에 유용
- 선형 모델, 신경망은 각 피처의 스케일, 분포에 밀접하게 영향
- 특히 피처와 타깃 간 비선형이 있다면 모델 만드는데 어려움
- log, exp함수는 데이터의 스케일을 변경, 선형 모델과 신경망의 성능 올리는데 도움
- 정수 카운트 데이터를 다룰 때 특히 도움이 된다 (로그인 수 등)
-
대부분 모델은 각 특성이 정규분포와 비슷할 때 최고의 성능

- 예를 들면 위와 같이 왜도가 있는 데이터는 선형 모델이 잘 학습하지 못함
# 로그 스케일 적용 ## 로그는 0값을 처리하지 못하므로, 1씩 더해줌 X_train_log = np.log(X_train+1) X_test_log = np.log(X_test+1)
- 가끔 회귀에서 피처뿐만 아니라 타깃 변수를 log스케일 적용하는 것도 효과적임
- 카운트(주문 횟수)를 예측하는 경우가 전형적으로 도움이 됨 log(y+1)
- 구간 분할, 다항식, 상호작용은 특히 선형 모델에서 효과적이니 꼭 기억
특성 자동 선택
요약
- 일변량 통계
- 모델 사용하지 않음
- 각 특성이 독립적으로 평가, 다른 특성과 관계가 깊은 특성은 배제
- p값을 기초하여 선택 (높은 p값은 제외)
- 모델 기반 특성 선택
- 지도 학습의 모델을 사용하여 특성 중요도 평가
- 학습 시 특성 평가한 모델을 쓸 필요 없음
- 랜덤 포레스트나, l1 규제 선형 모델 등..
- 반복적 특성 선택
- 앞에서 본 것처럼 특성을 만드는 방법은 많고, 쉬움
- 하지만, 특성이 추가되면 복잡해지며, 과대적합될 가능성도 높아짐
- 특성을 추가하거나, 고차원 데이터 사용 시, 유용한 특성만 선택하여 특성 수를 줄이는 것이 좋음
- 그럼 어떻게 특성을 선택할까?
- 일변량 통계(univariate statistics)
- 모델 기반 선택(model-based selection)
- 반복적 선택(iterative selection)
- 세 방법 모두 지도학습
- 타깃값이 필요함
- 훈련, 테스트 세트로 나눈 후, 훈련 데이터만 특성 선택에 사용해야 함
일변량 통계
- 개개의 특성과 타깃 사이 중요한 통계적 관계가 있는지 계산
- 관련이 깊다고 판단되는 특성을 선택
- 분류에서는 분산분석(ANOVA, analysis of variance)라고 함
- 핵심 요소는 일변량, 각 특성이 독립적으로 평가
- 다른 특성과 깊게 관련된 특성은 선택되지 않음
- scikit-learn에서는,
- 분류는 f_classif(기본값) / 회귀는 f_regression을 선택하여 테스트
- 계산한 p값에 기초하여 특성을 제외
- 높은 p값을 가진 특성을 제외할 수 있도록 매개변수 사용
- 매개변수 SelectKBest
- 고정된 k개의 특성을 선택
- 매개변수 SelectPercentile
- 지정된 비율만큼 선택
from sklearn.feature_selection import SelectPercentile select = SelectPercentile(percentile=50) select.fit(X_train, y_train) # 훈련 세트에 적용 X_train_selected = select.transform(X_train)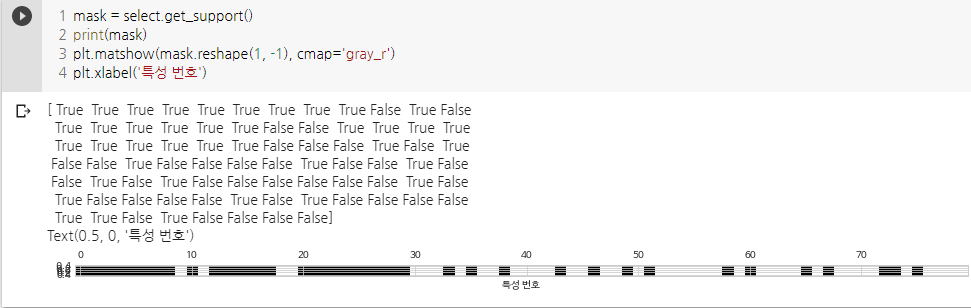
- 지정된 비율만큼 선택
- 선택한 특성 조회, 시각화
- 언제 쓸까?
- 너무 많은 피처들로 인해 모델을 만들기가 어려울 때
- 많은 피처들이 확실히 도움이 안 된다고 생각될 때
모델 기반 특성 선택
- 지도 학습 모델을 사용해서, 특성의 중요도 평가(feature_importances_ 속성)
- 특성의 중요도를 평가한 모델으로 학습하지 않아도 상관 없음
- 어떤 모델을 쓰면 될까?
- 결정트리 및 이를 기반으로 한 모델은 특성의 중요도가 담긴 f.i_를 제공
- 선형 모델 계수의 절대값도 특성의 중요도를 재는 데 사용 가능
- l1규제를 사용한 선형 모델은 일부 특성의 계수만 학습
- 모델 기반 특성 선택은 SelectFromModel에 구현
from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import RandomForestClassifier select = SelectFromModel(RandomForestClassifier(n_estimators=100, random_state=42), threshold='median')
반복적 특성 선택
- 특성 수가 각기 다른 모델이 만들어짐
- 방법 1)
- 특성을 하나도 선택하지 않고, 종료 조건에 도달할 때까지 하나씩 추가
- 방법 2)
- 모든 특성을 가진 채로 시작, 종료 조건대 도달할 때까지 하나씩 제거
- 일련의 모델들이 만들어지기 때문에, 계산 비용이 많이 드는 것이 특징, 단점
- 재귀적 특성 제거(RFE, recursive feature elimination)
- 모든 특성으로 시작하여, 특성 중요도가 낮은 것을 제거
- 제거한 특성을 빼고 나머지 특성 전체로 새로운 모델 생성
- 미리 정의한 특성 개수가 남을 때까지 계속 진행
- 모델 기반 선택에서처럼, 여기서 특성 중요도를 결정할 방법을 제공해야 함.
- 시간이 비교적 많이 소요됨
from sklearn.feature_selection import RFE select = RFE(RandomForestClassifier(n_estimators=100, random_state=42), n_features_to_select=40) select.fit(X_train, y_train)
댓글남기기