자연어 처리 그 기초적인 방법에 대해
업데이트:
2. 자연어와 단어의 분산 표현
밑바닥부터 시작하는 딥러닝2 (한빛미디어)의 내용을 정리한 포스트입니다.
2.1. 자연어 처리
한국어, 영어처럼 일상적으로 사람들이 이야기하는 언어를 자연어 라고 한다. 이 자연어를 컴퓨터가 알아 들을 수 있도록 처리하는 것을 ‘자연어 처리’라고 한다.
자연어가 아닌 Python을 생각해보자. print 라고 명령하면 그대로 출력하고, for 라고 이야기하면 몇 번이고 반복한다. 한 글자라도 틀리면 알아듣지 못하고, 같은 작업을 여러 형태로 표현하는 데에도 제약이 있다. 한 마디로, 유연하지 못하다. (책에선 ‘딱딱한 언어’라고 표현)
반면, 자연어는 상당히 유연하다. 한 가지 단어에 여러 뜻이 들어 있기도 하고, 뜻이 바뀌기도 하며 같은 뜻을 전하기 위해 표현할 수 있는 방법이 무수히 많다. 컴퓨터 언어보다 훨씬 유연하다.
이렇게 유연한 언어를, 유연하지 못한 컴퓨터에게 이해시키는 것은 어려운 작업이지만, 달성만 하면 컴퓨터에게 다채로운 일을 시킬 수 있다. 검색 엔진, 기계 번역, 질의응답 시스템, 입력기 전환, 문장 자동 요약 등 자연어 처리는 어렵지만 다양한 문제를 해결하는 데에 쓰일 수 있다.
2.1.1. 단어의 의미
우리가 일상적으로 쓰는 말들은 단어의 조합으로 구성된다. 말의 의미 또한 단어로 구성되어있다. 컴퓨터에게 단어의 의미를 이해시키는 방법은 크게 세 가지 방법이 있다.
- 시소러스를 활용 (thesaurus, 유의어사전)
- 통계 기반 기법
- 추론 기반 기법(word2vec)
먼저, 시소러스를 살펴보자.
2.2. 시소러스
백과사전을 생각해보자. 사전에서 ‘자동차’를 찾으면 ‘원동기를 장치하여~ 움직이도록 만든 차’ 라는 설명이 나올 것이다. 이런 식으로 단어들을 모두 정리해두면 컴퓨터도 단어의 의미를 이해할 수 있을 것이다.
단, 이 ‘사전’은 백과사전 형태가 아니라 시소러스 형태로 되어있다.
시소러스는, 뜻이 비슷한 단어들이 모여있는 유의어 사전이다. 자연어 처리에서 이용되는 시소러스는 유의어 뿐 아니라, 위계 등을 정의하는 경우가 있는데, 아래 사진이 그 예시이다.
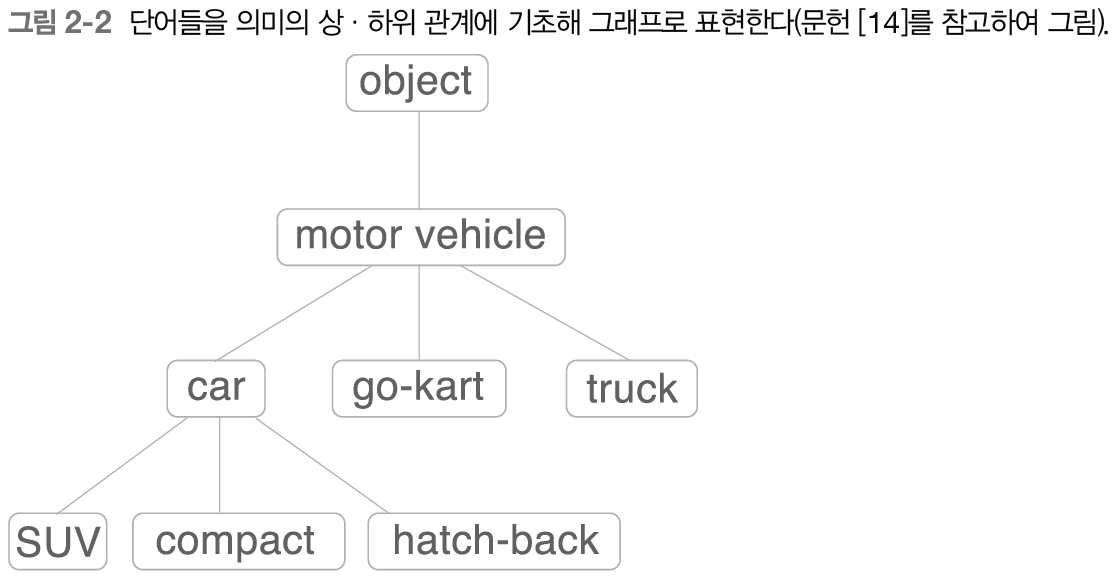
요런 단어 집합들을 많이 만들어서 컴퓨터에게 학습시키면 어떤 일을 시킬 수 있을까?
예를들면..
- 구글에 SUV를 검색하면 그와 비슷한 단어인 compact나, 상위 단어인 car를 노출시켜줌
이런 일을 할 수 있을 것이다.
2.2.1. WordNet
위에서 설명한 시소러스 중 가장 유명한 것은 WordNet이다. 1985년부터 구축한 근본있는 프로젝트인데, 얼마나 많은 사람들의 노력이 들어있을지 상상이 되지 않는다.
20만 개 이상의 단어가 들어있다고 한다.
2.2.2. 시소러스의 문제점
위에서 슬쩍 이야기했지만, 시소러스는 아래와 같은 단점들을 갖고 있다.
- 시대 변화에 반응하기 어려움
- 존맛, 인싸 등과 같은 신조어들을 시소러스에 반영하려면 하나씩 다시 넣어줘야 한다는 번거로움이 있다.
- 요새는 매 순간마다 신조어가 생기는데, 이러면 당연히 트렌드 반영을 하지 못한다.
- 사람의 노력이 (갈려)들어감
- 사람이 분류하는 작업이다 보니,(인간지능?!) 자연스럽게 비용 문제가 발생한다. (시간, 인력, 돈 등)
- 단어 간 미묘한 어감 차이를 표현할 수 없음.
- ‘레트로’와 ‘빈티지’라는 단어 사이에는 분명히 어떤 차이가 있지만, 시소러스로 이를 표현하려면?! 문제가 생긴다.
이런 문제들을 해결하기 위해 통계 기반 기법과 추론 기반 기법을 활용하곤 한다.
2.3. 통계 기반 기법
말뭉치(corpus)라는 개념이 나온다. 말뭉치는 연구나 프로젝트 등 특정 목적을 갖고 수집된 다량의 텍스트 데이터이다.
통계 기반 기법을 비록한 다양한 방법들의 목표는 이 말뭉치에서 핵심을 효율적으로 추출하는 것이다.
2.3.1. 파이썬으로 말뭉치 전처리하기
위키나 유명 소설 등보다는 일단 간단한 문장부터 전처리를 해보자.
‘You say goodbye and I say hello.’라는 단어가 있을 때, 이를 전처리하려면 어떻게 해아할까?
- 토큰화 (대문자를 모두 소문자로 만들기, 문장 부호를 없애기 등…)
- 고유한 단어들에 대해 id를 붙이기 (정수 인코딩과 유사한 작업)
def preprocess(text):
import re
p = re.compile('\w+')
text = text.lower()
text = p.findall(text)
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
print(corpus) # array([0, 1, 2, 3, 4, 1, 5])
print(word_to_id) # {'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5}
print(id_to_word) # {0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello'}
2.3.2. 단어의 분산 표현
색(color)에 대해 생각해보자. 같은 색을 두고, ‘코발트블루’라고 할 수도 있지만, 이를 (R, G, B): (0, 70, 140) 이라고 표현할 수도 있다.
후자처럼 벡터화시키는 것의 장점을 생각해보면
- 전자보다 더 정확하게 의미를 전달할 수 있다.
- 다른 색과의 비교가 쉽다. (예를 들어, (150, 0, 47)과 (140, 9, 49)는 모두 붉은 계열이고, 앞의 경우가 더 붉다는 것을 알 수 있다.)
- 모호한 뜻을 정량화할 수 있다.
색상을 벡터로 표현한 것처럼 단어 또한 벡터로 표현을 할 수 있다. 이를 자연어 처리 분야에서는 분산 표현(distributional representation)이라고 한다.
2.3.3. 분포 가설
분포 가설(distributional hypothesis)이란, ‘단어의 의미는 주변 단어(맥락)에 의해 형성된다, 즉, 비슷한 자리에 오는 단어는 비슷한 뜻을 의미한다.’ 라는 개념이다.
우리가 평소에 쓰는 말들을 생각해보자. ‘오늘 술을 마셨어!’, ‘사실 어제도 술을 들이켰어!’ 이 두 문장을 살펴보면, ‘술을’ 뒤에 ‘마셨어’ 와 ‘들이켰어’ 가 나오는데, 이 둘은 사실 같은 맥락에서 쓰였다.
결국 분포 가설은, 단어 자체에는 큰 의미가 없고, 맥락(context)이 의미를 형성한다는 것이다.

- 맥락이란, 특정 단어를 중심으로 한 주변 단어들을 의미한다.
- 위 그림에서는 윈도우 크기(맥락 크기)가 2이다.
- 상황에 따라서는 왼쪽 혹은 오른쪽 단어만 사용할 수도 있고, 문장의 시작과 끝을 고려할 수도 있다.
2.3.4. 동시 발생 행렬
분포 가설을 기반으로, 단어를 벡터화하는 것을 생각해보자. 특정 단어에 집중하고, 그 주변(윈도우 크기)에 어떤 단어가 몇 번 등장했는지 세보면 될 것이다. (이 책에선 이걸 ‘통계 기반 기법’이라고 함)
- you say goodbye and i say hello. 라는 단어를 분산 표현하면, [0 1 2 3 4 1 5 6]가 된다. (이번엔 구두점까지 표현(6))
-
you에 초점을 맞춰 윈도우 크기가 1일 때 단어 빈도를 나타내면, [0, 1, 0, 0, 0, 0, 0]이 된다.
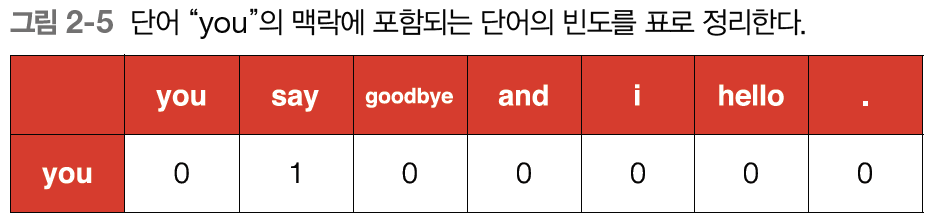
-
이 작업을 모든 단어들에 대해 수행하면 아래와 같은 행렬로 표현할 수 있다.
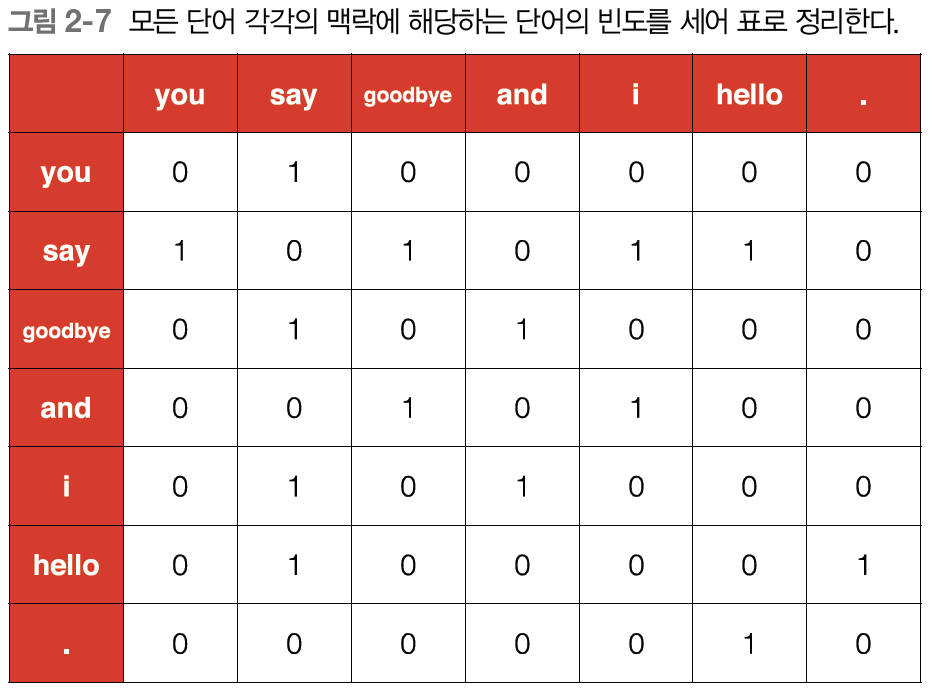
-
위 표는 주어진 모든 단어들에 대해 동시발생하는 단어를 표에 정리한 것이고, 행렬의 형태를 띈다고 하여 동시발생 행렬(co-occurrence matrix)라고 한다.
-
2.3.5. 벡터 간 유사도
벡터들이 모여있다면 이 벡터들이 얼마나 유사한지 어떻게 측정할 수 있을까? 벡터 간 유사도를 측정하는 방법은 내적, 유클리드 거리 등이 있다. 단어 벡터의 유사도를 나타날 때에는 코사인 유사도(cosine simillarity)를 주로 이용한다.
- 코사인 유사도
- $\text{similarity}(x,y)=\frac{\vec{x}\cdot\vec{y}}{|\vec{x}||\vec{y}|} = \frac{x_1y_1+\cdots+x_ny_n}{\sqrt{x^2_1+\cdots+x_n^2}\sqrt{y_1^2+\cdots+y_n^2}}$
- 분자에는 벡터의 내적, 분모에는 각 벡터의 노름이 등장한다. (L2 norm)
- 값은 -1과 1 사이이며, 코사인 유사도를 직관적으로 이해하자면 ‘두 벡터가 가리키는 방향이 얼마나 유사한가?’ 이다.
- 값이 1이면 방향이 같고, -1이면 반대이다.
이번엔 위의 내용을 바탕으로 you say goodbye and i say hello. 라는 문장에서 ‘you’와 가장 유사한 단어들을 코사인 유사도로 계산하여 top3를 뽑아봤다.
- hello: 0.9999999800000005
- goodbye: 0.7071067691154799
- i: 0.7071067691154799
‘you’와 ‘i’의 유사도는 모두 인칭을 나타내는 말이므로 수치가 이해되는데, ‘hello’와 ‘goodbye’는 이해가 되지 않는다. 이것은 corpus가 너무 작아서 발생하는 현상이며, 데이터가 커지면 개선될 수 있다.
이제 통계 기반 기법을 어떻게 더 개선할 수 있는지 공부해보자.
2.4. 통계 기반 기법 개선하기
위에서 살펴봤던 내용 중 동시발생 행렬을 개선해보자.
2.4.1. 상호정보량
동시발생 행렬은 두 단어가 동시에 발행한 횟수를 나타낸다. 두 단어가 데이터에서 계속 동시에 나타난다면 그 단어들은 관련이 깊다고 볼 수도 있겠다. 하지만 이런 경우를 생각해보자.
말뭉치에서 ‘the’와 ‘car’ 그리고 ‘drive’라는 단어가 있다고 가정해보자. the car… 라는 문구가 car drive… 라는 문구보다 더 많이 등장했을 것이다. 의미론적으론 drive가 car와 더 연관있지만, 동시발생 행렬에선 the라는 단어가 car와 더 연관이 있다고 결론을 내버리는 것이다.
이를 방지하기 위해 점별 상호정보량(PMI, Pointwise Mutual Informatioin)이라는 척도를 사용한다.
- $\text{PMI}(x,y)=\log_2{\frac{P(x,y)}{P(x)P(y)}}$
- 이 PMI값이 높을수록 관련성이 높다는 의미가 된다.
- 이 식을 동시발생 행렬을 사용하여 다시 표현해보자.
- $\text{PMI}(x,y)=\log_2{\frac{P(x,y)}{P(x)P(y)}} = \log_2{\frac{C(x,y)\div{N}}{({C(x)}\div{N})({C(y)}\div{N})}} = \log_2{\frac{C(x,y)\cdot{N}}{C(x)C(y)}}$
- $C$: 동시발생 행렬
- $C(x, y)$: 단어 $x$와 $y$가 동시발생하는 횟수
- $C(x), C(y)$: 각 단어의 등장 횟수
- $N$: 말뭉치에 포함된 단어 수
자연어에 바로 적용해보자. 10,000개 단어로 이뤄진 말뭉치가 있을 때, ‘the’, ‘car’, ‘drive’가 각각 1,000, 20, 10번씩 등장했다고 하자. 그리고 ‘the’, ‘car’의 동시 발생 횟수는 10회, ‘car’, ‘drive’의 동시 발생 횟수는 5회라고 해보자. 이 때 각각의 PMI를 구해보면,
- $\text{PMI}(\text{the},\text{car})=\log_2{\frac{10\cdot{10000}}{1000\cdot{20}}} \approx 2.32$
- $\text{PMI}(\text{car},\text{drive})=\log_2{\frac{5\cdot{10000}}{20\cdot{10}}} \approx 7.97$
[‘the’와 ‘car’]보다 [‘car’, ‘drive’]가 더 관련성이 높다고 나오는 것을 알 수 있다. 동시 발생 횟수 자체는 전자가 더 높지만, 단독으로 출현하는 경우까지 고려하므로 위와 같은 결과가 나오는것이다.
이런 PMI지표에도 문제점이 있는데, PMI 수식 내에 있는 log때문에 발생하는 경우이다.
만약 동시발생 횟수가 0이면 $\log_2{0}$이 되므로, 이런 경우를 피하기 위해 양의 상호정보량(Positive PMI, PPMI)를 사용한다. 말이 어렵지, 사실은 양의 값이 아니면 0을 내보내는것이다.
- $\text{PPMI}(x,y)=\text{max}(0,\text{PMI}(x,y))$
계속 사용하고있는 ‘You say goodbye and I say hello.’에 대한 PPMI행렬을 나타내보자.
-
PPMI행렬

이제 동시발생 행렬보다 더 의미가 있는 형태를 얻게되었다. 그런데 이렇게 좋은 PPMI행렬도 크나큰 문제점이 있는데…
말뭉치에 있는 단어 수만큼의 차원을 가진 행렬이 만들어진다. 만약 말뭉치에 단어가 300만개라면, 300만개의 차원을 다루어야한다. 이 문제를 어떻게 해결할 수 있을까?
2.4.2. 차원 축소
머신러닝 모델링을 할 때도 나오는 차원 축소를 통해 PPMI행렬의 차원을 축소시킬 수 있다.
차원 축소의 핵심은 단순히 차원을 축소시키는 것이 아닌, 중요한 정보는 유지하며 줄이는 것이다.
-
이 그림이 직관적..!
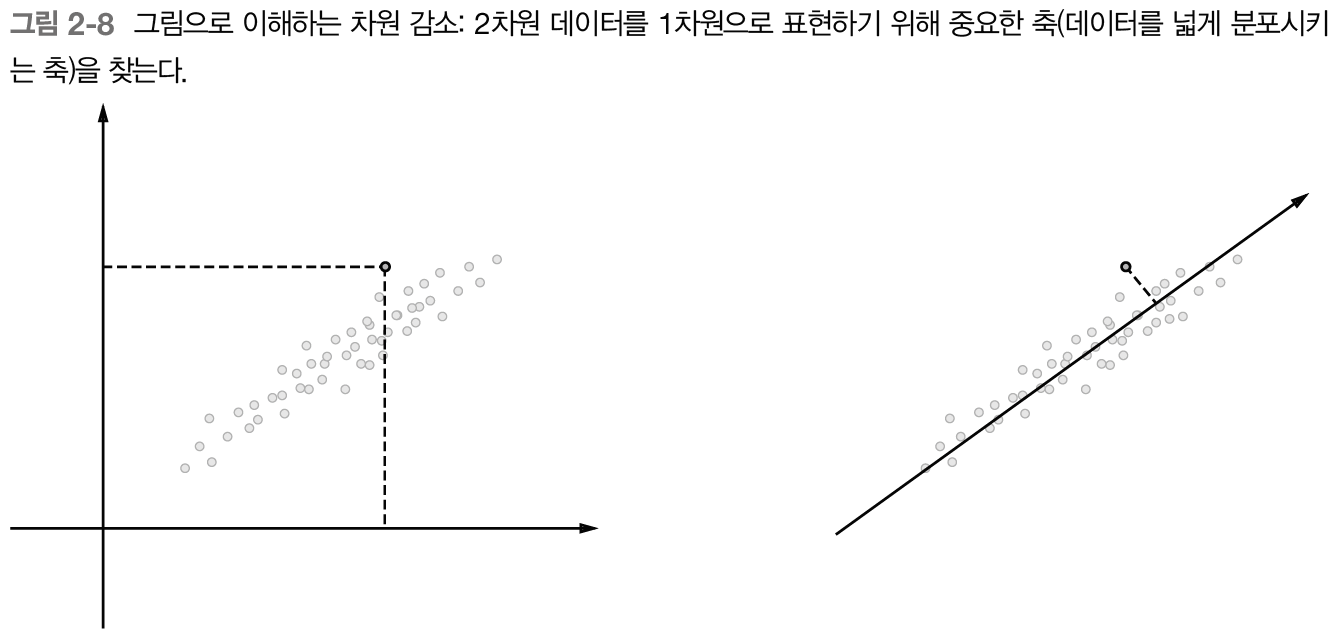
-
PPMI행렬과 같이 대부분 0인 값으로 구성된 행렬을 희소행렬(sparse matrix)이라고 하는데, 차원 축소의 결과로 만들어진 행렬은 대부분 0이 아닌 값으로 이루어진 ‘밀집벡터’로 변환된다.
2.4.3 SVD에 의한 차원 축소
여러가지 차원 축소 방법들이 있지만, 그 중에서 SVD를 활용하여 차원 축소를 해보자. (SVD에 대한 자세한 설명은 생략)
-
numpy로 SVD 구현

- 희소 벡터가 특잇값 분해를 거쳐 밀집 벡터로 변한 것을 확인할 수 있다.
그러면 모든 단어를 2차원 벡터로 나타낸 후, 이를 시각화해보자!
-
시각화 결과
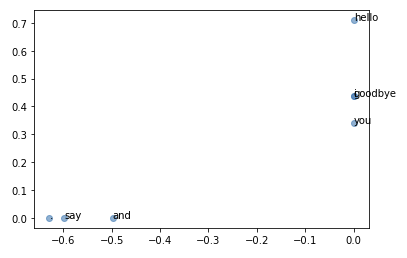
‘goodbye’, ‘hello’가, 그리고 ‘i’와 ‘you’(아이유?!)가 꽤 가깝게 위한 것을 알 수 있다. 다만, 데이터셋 자체가 작기 때문에 그대로 결과를 받아들이기엔 무리가 있긴 하다. (차원이 축소되는 내용 자체에 포커싱!)
요약
- 사전과 비슷한.. 시소러스 기반의 기법은 인적 자원이 매우 많이 들어간다. 그리고 업데이트에도 큰 비용이 발생한다.
- 현재는 말뭉치를 이용, 단어를 벡터화하는 방법을 주로 사용한다.
- 최근의 단어 벡터화 기법들은 대부분 ‘단어 의미는 주변 단어에 의해 형성된다’라는 분포 가설에 기초한다.
- 통계 기반 기법은 말뭉치 안의 각 단어에 대해 그 주변 단어들의 빈도를 집계한다. (동시발생 행렬)
- 동시발생 행렬을 PPMI행렬로 변환하고, 차원을 축소시킨다. 이 과정을 거치면 매우 큰 차원을 가진 희소 벡터에서 차원이 감소된 밀집 벡터로 변환할 수 있다.
- 단어의 벡터 공간에서는 의미가 가까운 단어는 그 거리도 가까울 것으로 기대된다.
댓글남기기